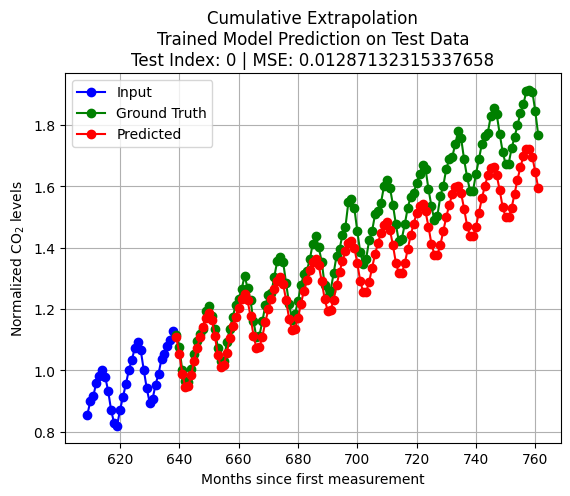
import numpy as npimport matplotlib.pyplot as pltimport pandas as pdfrom sklearn.preprocessing import StandardScalerimport torchimport torch.nn as nnimport torch.nn.functional as Ffrom torch.utils.data import TensorDataset, DataLoaderif (torch.cuda.is_available()): device = torch.device("cuda")else: device = torch.device("cpu")print(f"Supported Device: {device}")
Supported Device: cpu
Loading the data
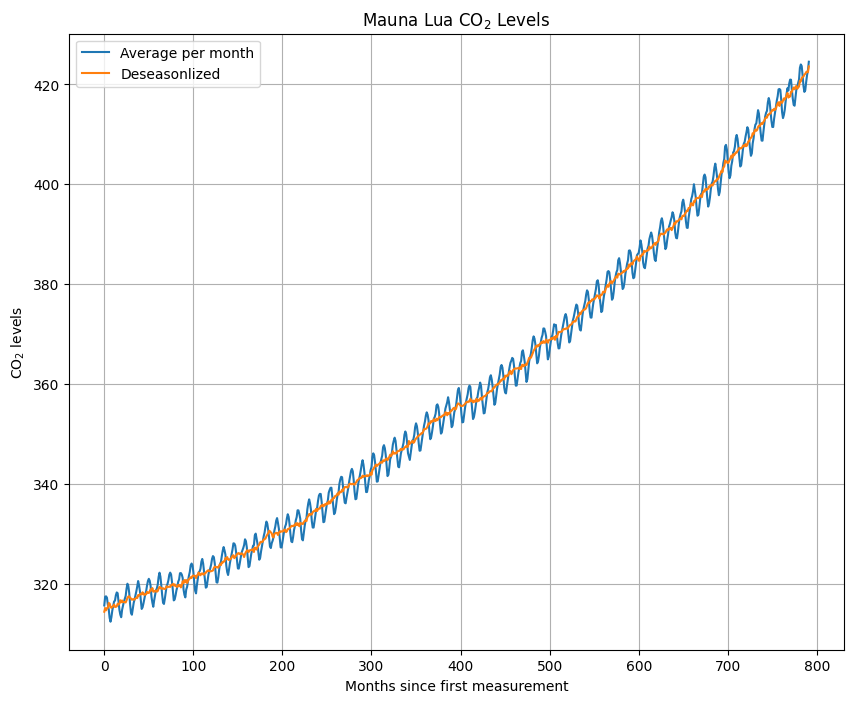
Mauna Lua CO2 Dataset - https://gml.noaa.gov/webdata/ccgg/trends/co2/co2_mm_mlo.csv
df = pd.read_csv('co2_mm_mlo.csv')df
year
month
decimal date
average
deseasonalized
ndays
sdev
unc
0
1958
3
1958.2027
315.70
314.43
-1
-9.99
-0.99
1
1958
4
1958.2877
317.45
315.16
-1
-9.99
-0.99
2
1958
5
1958.3699
317.51
314.71
-1
-9.99
-0.99
3
1958
6
1958.4548
317.24
315.14
-1
-9.99
-0.99
4
1958
7
1958.5370
315.86
315.18
-1
-9.99
-0.99
...
...
...
...
...
...
...
...
...
787
2023
10
2023.7917
418.82
422.12
27
0.47
0.17
788
2023
11
2023.8750
420.46
422.46
21
0.91
0.38
789
2023
12
2023.9583
421.86
422.58
20
0.68
0.29
790
2024
1
2024.0417
422.80
422.45
27
0.73
0.27
791
2024
2
2024.1250
424.55
423.61
18
1.31
0.59
792 rows × 8 columns
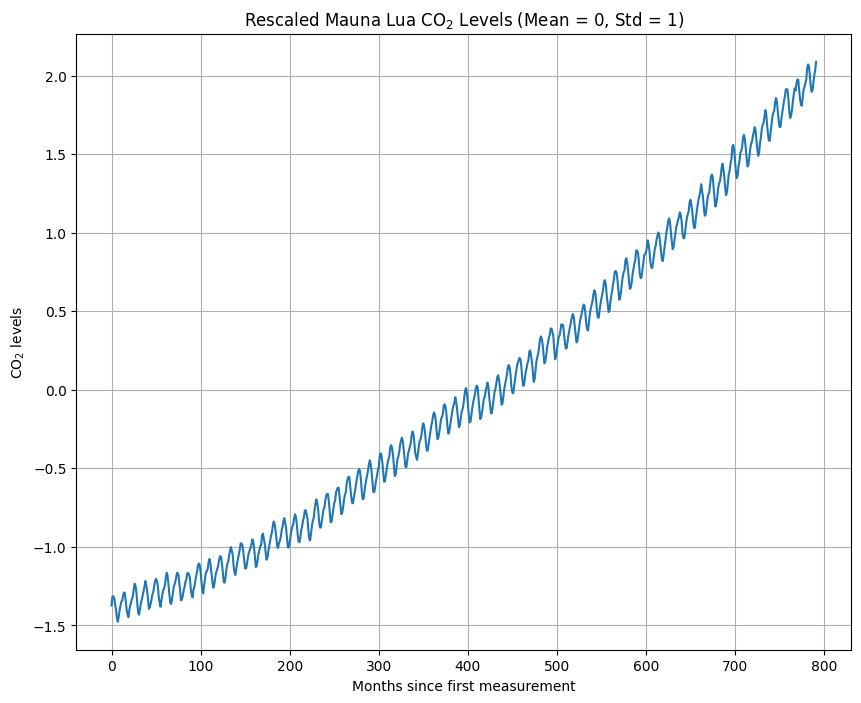
fig = plt.figure(figsize=(10,8))plt.title(r'Mauna Lua CO$_2$ Levels')plt.plot(df.index, df['average'])plt.plot(df.index, df['deseasonalized'])plt.xlabel('Months since first measurement')plt.ylabel(r'CO$_2$ levels')plt.grid()plt.legend(['Average per month', 'Deseasonlized'])plt.show()
Creating features
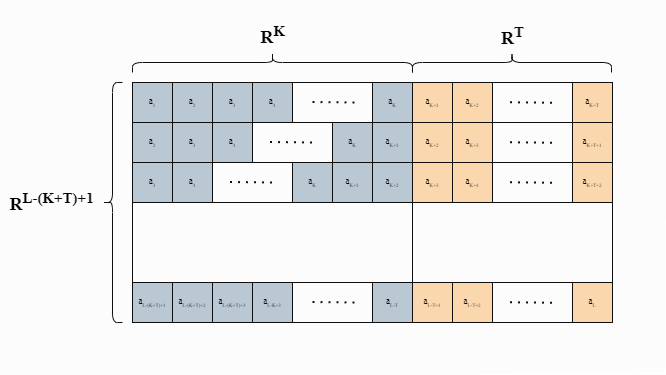
L = Number of Samples K = Feature Window Size T = Label Window Size
MA (Moving Average) and ARMA (Auto Regressive Moving Average)
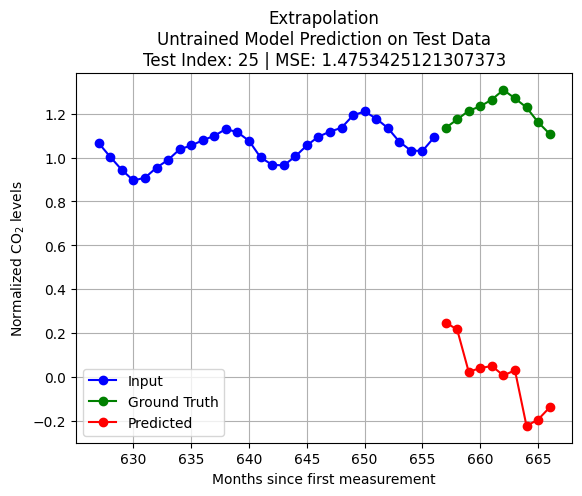
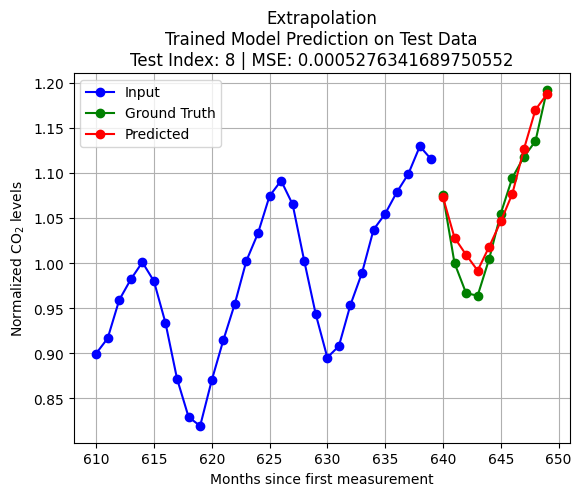
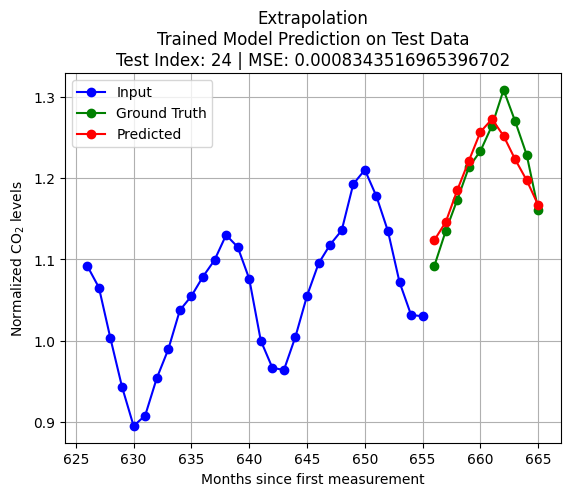
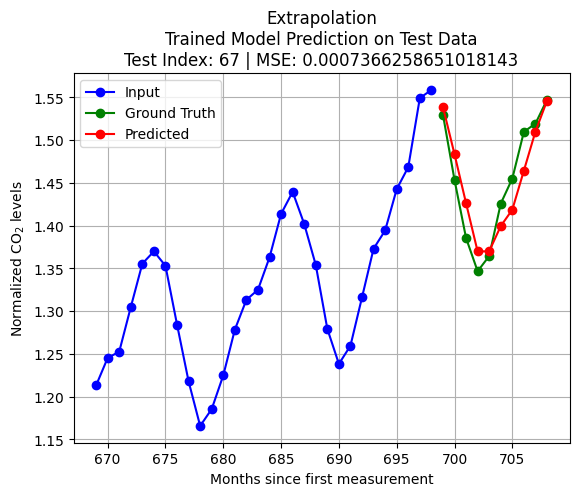
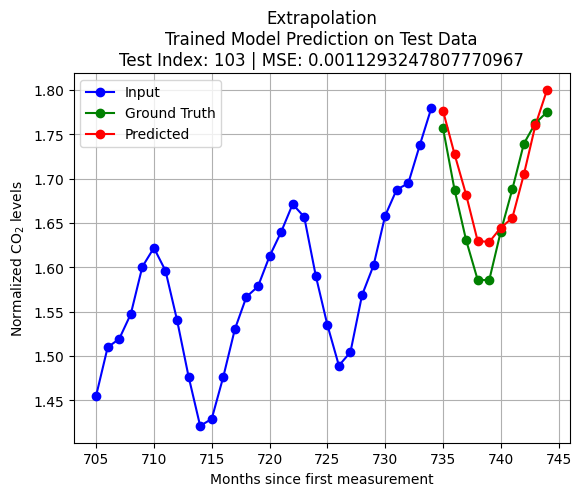
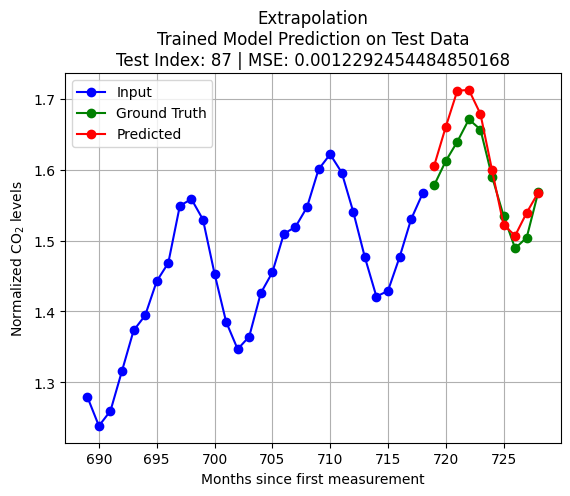
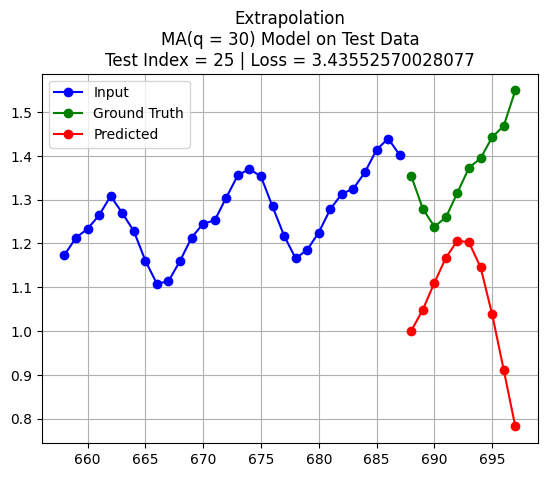
import pandas as pdfrom statsmodels.tsa.arima.model import ARIMAX_train = pd.Series(scaled_D[:int(len(scaled_D)*train_size)].reshape(-1,))X_test = pd.Series(scaled_D[int(len(scaled_D)*train_size)+test_index:int(len(scaled_D)*train_size)+K+test_index].reshape(-1,))q = Kmodel = ARIMA(X_train, order=(0, 0, q)) # (autoregressive = 0, differencing = 0, moving average = q)model_fit = model.fit()forecast = model_fit.forecast(steps=pred_len)y_test = scaled_D[int(len(scaled_D)*train_size)+K+test_index:int(len(scaled_D)*train_size)+K+pred_len+test_index]loss = np.linalg.norm(y_test - forecast.to_numpy(),2)plt.plot(np.arange(int(len(scaled_D)*train_size)+test_index,int(len(scaled_D)*train_size)+test_index+K,1),X_test, 'bo-')plt.title(f'Extrapolation\nMA(q = {q}) Model on Test Data\nTest Index = {test_index} | Loss = {loss}')plt.plot(np.arange(int(len(scaled_D)*train_size)+test_index+K,int(len(scaled_D)*train_size)+test_index+K+pred_len,1),y_test, 'go-')plt.plot(np.arange(int(len(scaled_D)*train_size)+test_index+K,int(len(scaled_D)*train_size)+test_index+K+pred_len,1),forecast, 'ro-')plt.legend(['Input', 'Ground Truth', 'Predicted'])plt.grid()plt.show()
f:\D\Python\.venv\Lib\site-packages\statsmodels\tsa\statespace\sarimax.py:978: UserWarning: Non-invertible starting MA parameters found. Using zeros as starting parameters.
warn('Non-invertible starting MA parameters found.'
f:\D\Python\.venv\Lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
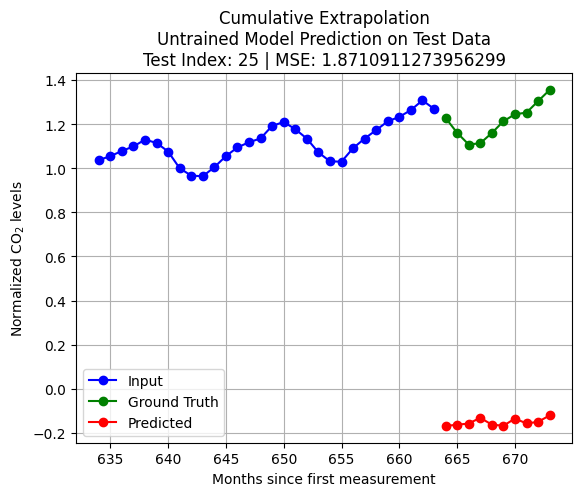
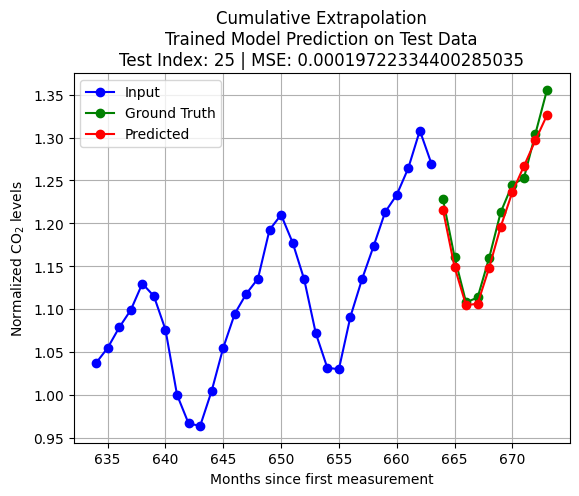
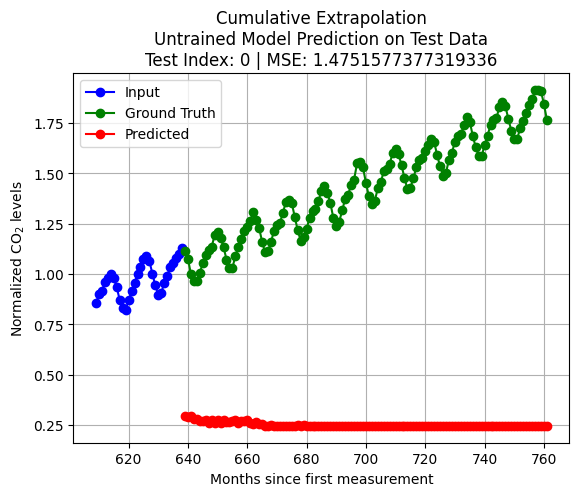
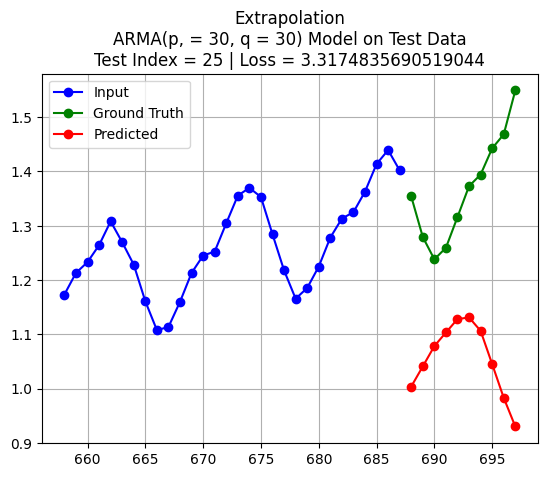
import pandas as pdfrom statsmodels.tsa.arima.model import ARIMAX_train = pd.Series(scaled_D[:int(len(scaled_D)*train_size)].reshape(-1,))X_test = pd.Series(scaled_D[int(len(scaled_D)*train_size)+test_index:int(len(scaled_D)*train_size)+K+test_index].reshape(-1,))q = Kp = Kmodel = ARIMA(X_train, order=(p, 0, q)) # (autoregressive = p, differencing = 0, moving average = q)model_fit = model.fit()forecast = model_fit.forecast(steps=pred_len)y_test = scaled_D[int(len(scaled_D)*train_size)+K+test_index:int(len(scaled_D)*train_size)+K+pred_len+test_index]loss = np.linalg.norm(y_test - forecast.to_numpy(),2)plt.plot(np.arange(int(len(scaled_D)*train_size)+test_index,int(len(scaled_D)*train_size)+test_index+K,1),X_test, 'bo-')plt.title(f'Extrapolation\nARMA(p, = {p}, q = {q}) Model on Test Data\nTest Index = {test_index} | Loss = {loss}')plt.plot(np.arange(int(len(scaled_D)*train_size)+test_index+K,int(len(scaled_D)*train_size)+test_index+K+pred_len,1),y_test, 'go-')plt.plot(np.arange(int(len(scaled_D)*train_size)+test_index+K,int(len(scaled_D)*train_size)+test_index+K+pred_len,1),forecast, 'ro-')plt.legend(['Input', 'Ground Truth', 'Predicted'])plt.grid()plt.show()
f:\D\Python\.venv\Lib\site-packages\statsmodels\tsa\statespace\sarimax.py:966: UserWarning: Non-stationary starting autoregressive parameters found. Using zeros as starting parameters.
warn('Non-stationary starting autoregressive parameters'
f:\D\Python\.venv\Lib\site-packages\statsmodels\tsa\statespace\sarimax.py:978: UserWarning: Non-invertible starting MA parameters found. Using zeros as starting parameters.
warn('Non-invertible starting MA parameters found.'
f:\D\Python\.venv\Lib\site-packages\statsmodels\base\model.py:607: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "