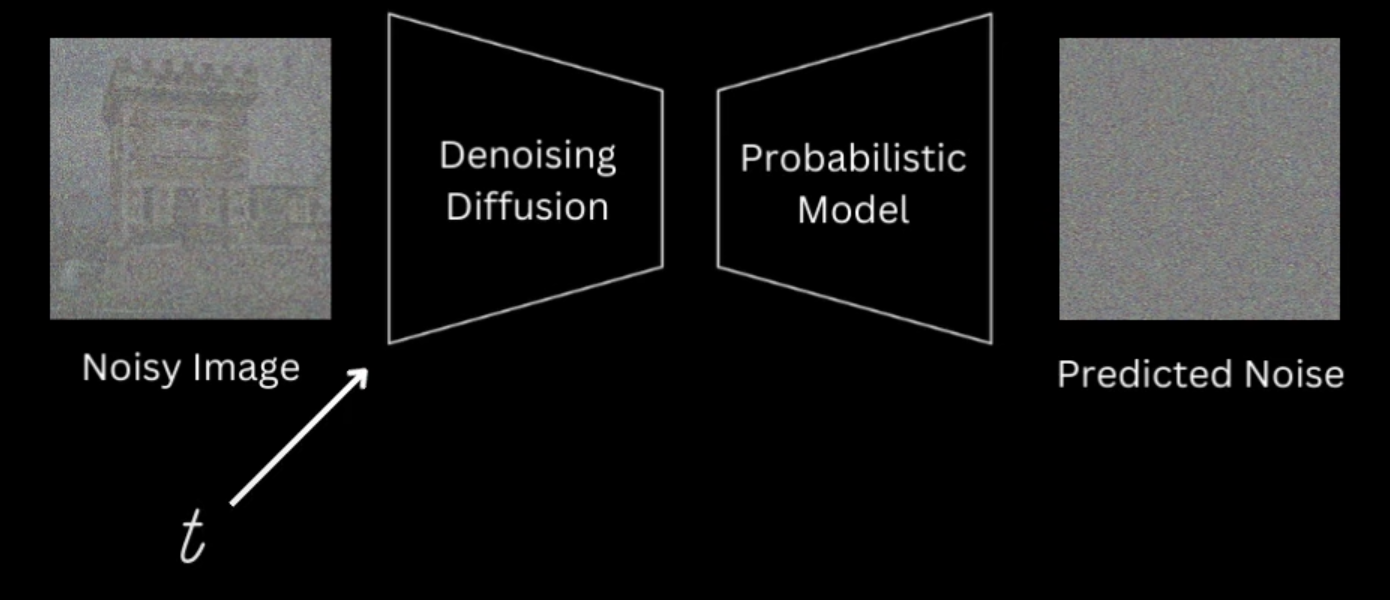
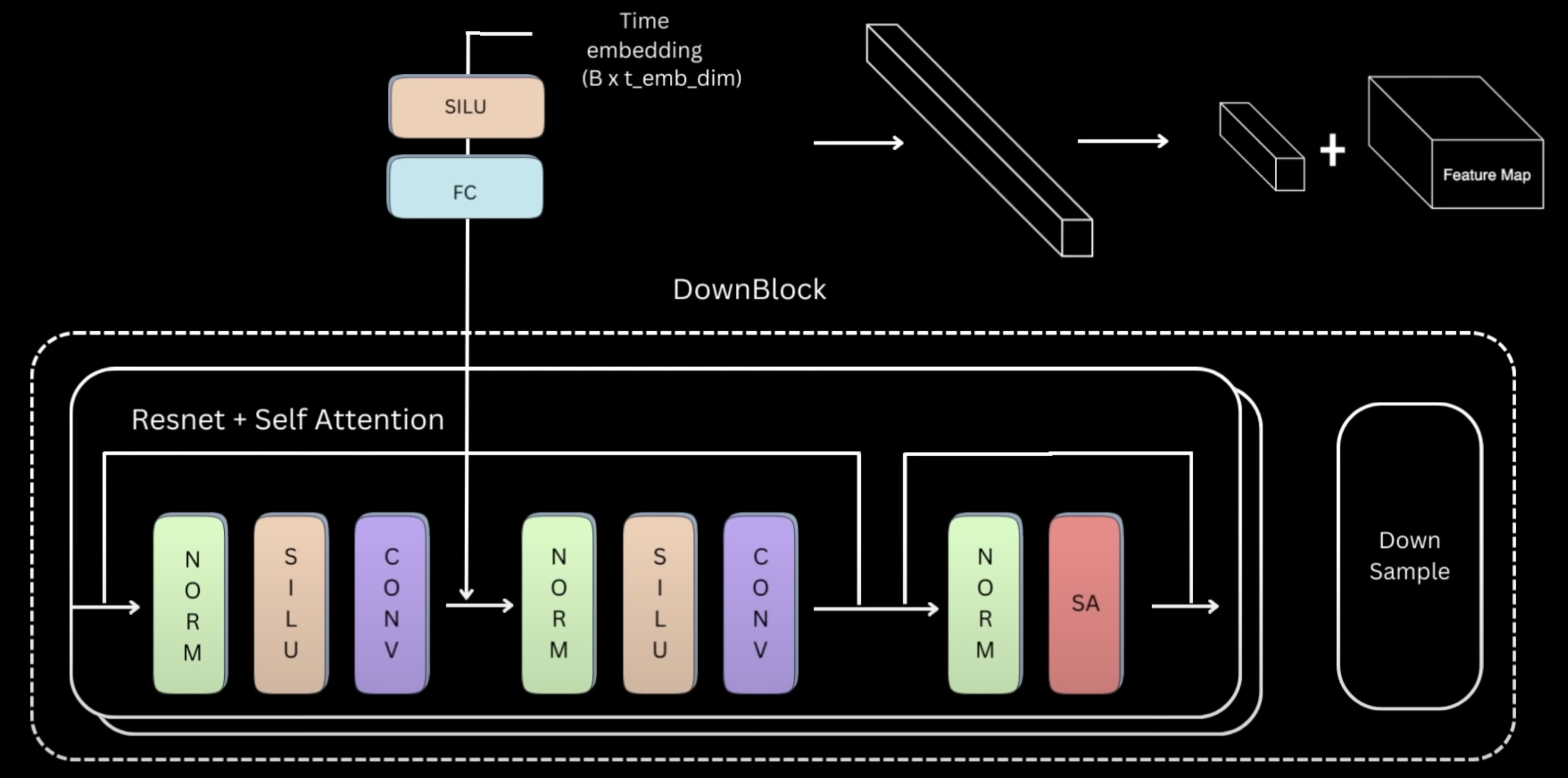
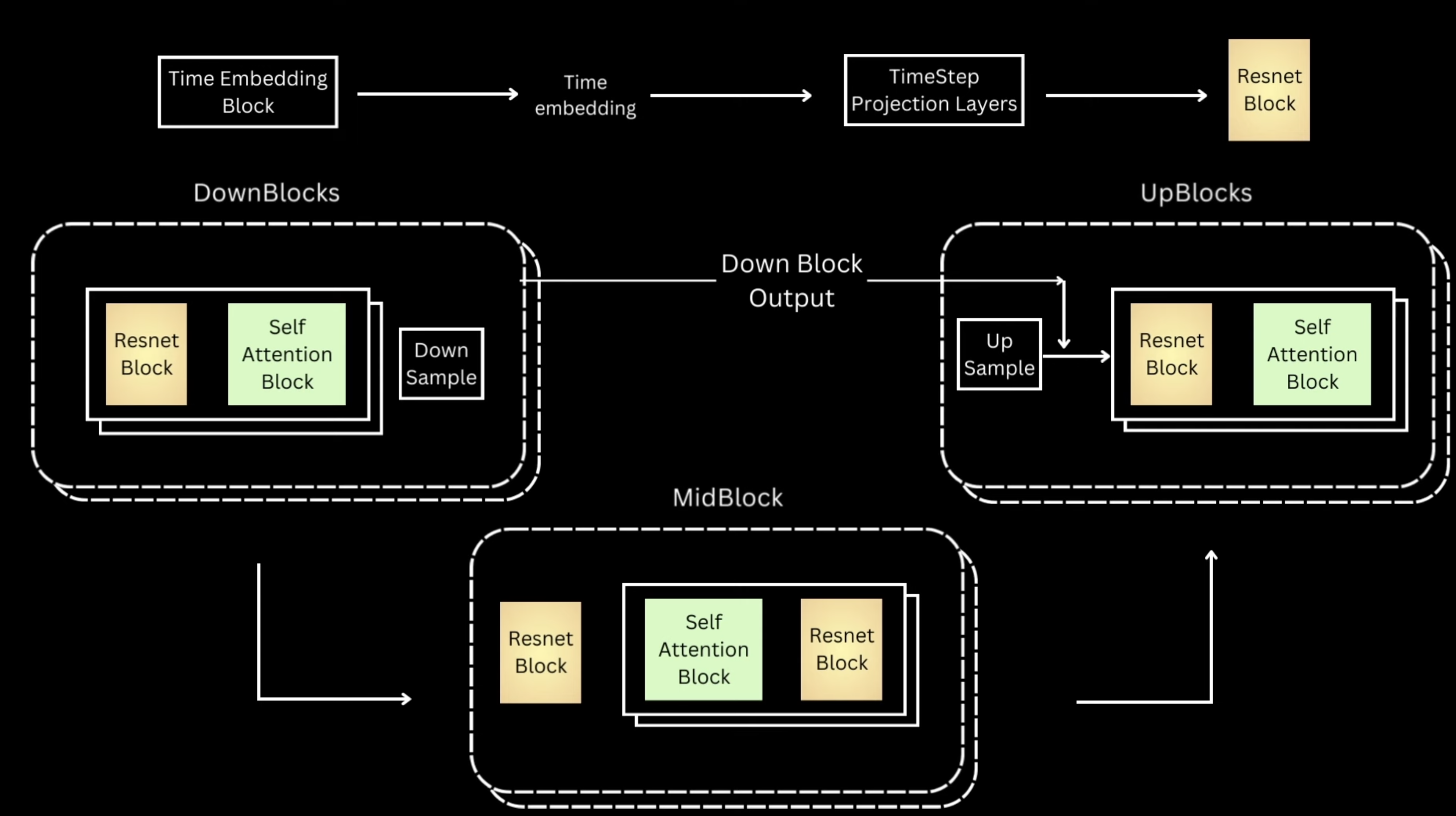
UNet(
(t_proj): Sequential(
(0): Linear(in_features=128, out_features=128, bias=True)
(1): SiLU()
(2): Linear(in_features=128, out_features=128, bias=True)
)
(conv_in): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(downs): ModuleList(
(0): DownBlock(
(resnet_conv_first): Sequential(
(0): GroupNorm(8, 32, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(t_emb_layers): Sequential(
(0): SiLU()
(1): Linear(in_features=128, out_features=64, bias=True)
)
(resnet_conv_second): Sequential(
(0): GroupNorm(8, 64, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(attention_norm): GroupNorm(8, 64, eps=1e-05, affine=True)
(attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=64, out_features=64, bias=True)
)
(residual_input_conv): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1))
(down_sample_conv): Conv2d(64, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
)
(1): DownBlock(
(resnet_conv_first): Sequential(
(0): GroupNorm(8, 64, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(t_emb_layers): Sequential(
(0): SiLU()
(1): Linear(in_features=128, out_features=128, bias=True)
)
(resnet_conv_second): Sequential(
(0): GroupNorm(8, 128, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(attention_norm): GroupNorm(8, 128, eps=1e-05, affine=True)
(attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True)
)
(residual_input_conv): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1))
(down_sample_conv): Conv2d(128, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
)
(2): DownBlock(
(resnet_conv_first): Sequential(
(0): GroupNorm(8, 128, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(t_emb_layers): Sequential(
(0): SiLU()
(1): Linear(in_features=128, out_features=256, bias=True)
)
(resnet_conv_second): Sequential(
(0): GroupNorm(8, 256, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(attention_norm): GroupNorm(8, 256, eps=1e-05, affine=True)
(attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(residual_input_conv): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))
(down_sample_conv): Identity()
)
)
(mids): ModuleList(
(0): MidBlock(
(resnet_conv_first): ModuleList(
(0-1): 2 x Sequential(
(0): GroupNorm(8, 256, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(t_emb_layers): ModuleList(
(0-1): 2 x Sequential(
(0): SiLU()
(1): Linear(in_features=128, out_features=256, bias=True)
)
)
(resnet_conv_second): ModuleList(
(0-1): 2 x Sequential(
(0): GroupNorm(8, 256, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(attention_norm): GroupNorm(8, 256, eps=1e-05, affine=True)
(attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(residual_input_conv): ModuleList(
(0-1): 2 x Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
)
)
(1): MidBlock(
(resnet_conv_first): ModuleList(
(0): Sequential(
(0): GroupNorm(8, 256, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): Sequential(
(0): GroupNorm(8, 128, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(t_emb_layers): ModuleList(
(0-1): 2 x Sequential(
(0): SiLU()
(1): Linear(in_features=128, out_features=128, bias=True)
)
)
(resnet_conv_second): ModuleList(
(0-1): 2 x Sequential(
(0): GroupNorm(8, 128, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(attention_norm): GroupNorm(8, 128, eps=1e-05, affine=True)
(attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True)
)
(residual_input_conv): ModuleList(
(0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))
)
)
)
(ups): ModuleList(
(0): UpBlock(
(resnet_conv_first): Sequential(
(0): GroupNorm(8, 256, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(256, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(t_emb_layers): Sequential(
(0): SiLU()
(1): Linear(in_features=128, out_features=64, bias=True)
)
(resnet_conv_second): Sequential(
(0): GroupNorm(8, 64, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(attention_norm): GroupNorm(8, 64, eps=1e-05, affine=True)
(attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=64, out_features=64, bias=True)
)
(residual_input_conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(up_sample_conv): Identity()
)
(1): UpBlock(
(resnet_conv_first): Sequential(
(0): GroupNorm(8, 128, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(t_emb_layers): Sequential(
(0): SiLU()
(1): Linear(in_features=128, out_features=32, bias=True)
)
(resnet_conv_second): Sequential(
(0): GroupNorm(8, 32, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(attention_norm): GroupNorm(8, 32, eps=1e-05, affine=True)
(attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=32, out_features=32, bias=True)
)
(residual_input_conv): Conv2d(128, 32, kernel_size=(1, 1), stride=(1, 1))
(up_sample_conv): ConvTranspose2d(64, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
)
(2): UpBlock(
(resnet_conv_first): Sequential(
(0): GroupNorm(8, 64, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(64, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(t_emb_layers): Sequential(
(0): SiLU()
(1): Linear(in_features=128, out_features=16, bias=True)
)
(resnet_conv_second): Sequential(
(0): GroupNorm(8, 16, eps=1e-05, affine=True)
(1): SiLU()
(2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(attention_norm): GroupNorm(8, 16, eps=1e-05, affine=True)
(attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=16, out_features=16, bias=True)
)
(residual_input_conv): Conv2d(64, 16, kernel_size=(1, 1), stride=(1, 1))
(up_sample_conv): ConvTranspose2d(32, 32, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
)
)
(norm_out): GroupNorm(8, 16, eps=1e-05, affine=True)
(conv_out): Conv2d(16, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)